

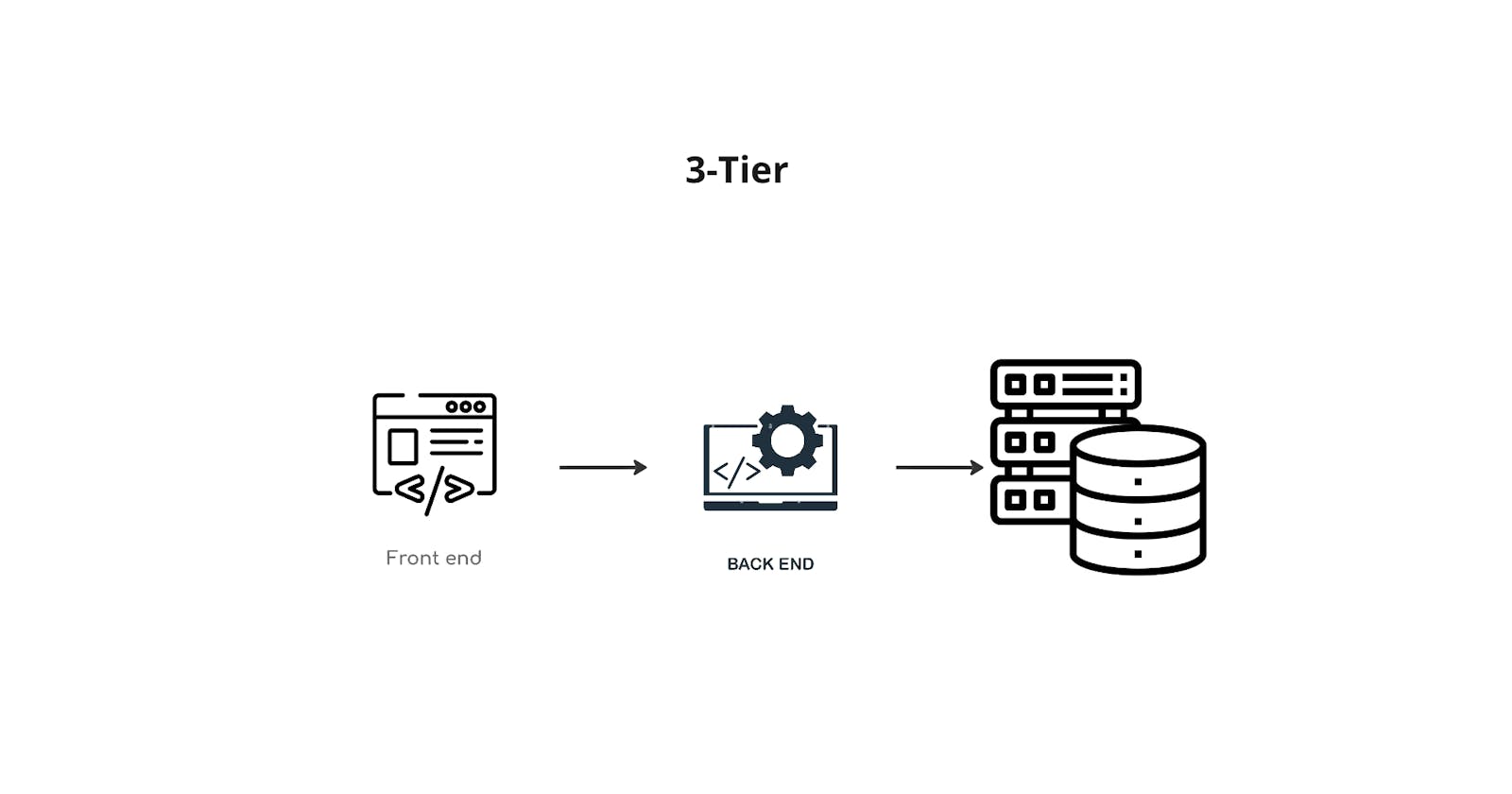
In this Blog post, we'll explore Kubernetes by setting up an environment from scratch: a master node and two workers.
Our goal? To deploy a 3-tier app: a web server (Apache) representing our frontend, Node.js presenting the backend, and PostgreSQL will be our Databasse. While we won't delve into code, we'll focus on setting up the architecture. Join us as we navigate Kubernetes, uncovering its prowess in orchestrating multi-tier deployments. Let's get into it.
Prerequisites:
A Kubernetes cluster (locally or in the cloud)
An editor (such as VS Code) for editing configuration files
Git installed on your system
GIthub for Source Code Management
Basic knowledge of Kubernetes concepts
What is Kubernetes ? Check out my previous blog to understand the basics of Kubernetes
https://gatete.hashnode.dev/k8s-up-running
How to installing a Kubernetes cluster locally check out this link below
https://gatete.hashnode.dev/simple-kubernetescluster-setup-with-kubespray
I have my cluster ready here using the above link to bootsrap

Since I have the code on Github let me clone it


For the FrontEnd let us setup an apache web server
Create a new YAML file named frontend-kube-app.yml.
apiVersion: v1
kind: Service
metadata:
name: web-httpd-service
spec:
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
selector:
app: web-httpd
---
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-httpd-deployment
spec:
selector:
matchLabels:
app: web-httpd
replicas: 10
template:
metadata:
labels:
app: web-httpd
spec:
containers:
- name: web-httpd
image: httpd:2.4.55
ports:
- containerPort: 80
This YAML file defines a Kubernetes Deployment for a frontend web service using Apache HTTP Server (httpd). Let's break it down:
apiVersion: Specifies the Kubernetes API version being used, in this case,
apps/v1.kind: Indicates the type of Kubernetes resource being defined, which is a Deployment.
metadata: Contains metadata about the Deployment, including the name (
web-httpd-deployment).spec: Describes the desired state of the Deployment.
a. selector: Defines how the Deployment selects which Pods to manage. In this case, it matches Pods with the label
app: web-httpd.b. replicas: Specifies the desired number of replicas (Pods) for the Deployment, set to 10.
c. template: Specifies the Pod template used to create new Pods for the Deployment.
Now, let's move on to deploying our pods and service. This step is straightforward. All we need to do is apply the configuration and specify the location of our YAML file.
kato@master1:~/3-tier$ kubectl apply -f ./frontend/frontend-kube-app.yml
service/web-httpd-service created
deployment.apps/web-httpd-deployment created
kato@master1:~/3-tier$
We can run kubectl get all -o wide to get all the service and pod details for our cluster.
Now, let's verify if we can access the web server by navigating to any of our node's IP addresses along with the NodePort port number. To obtain a node's IP address, we can use the following command:
kubectl get nodes -o wide
kubectl get all -o wide


Now that we've successfully deployed our frontend tier, let's move on to deploying the backend application tier. This process will be similar to what we did for the frontend, but with specifications tailored to our backend requirements.
Since we're not dealing with any application source code or connections at this stage, we'll keep it simple. In the backend directory, let's create a new YAML file named backend-kube-app.yml. This file will contain the configuration for deploying our backend application.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nodejs-app-deployment
spec:
selector:
matchLabels:
app: nodejs-app
replicas: 4
template:
metadata:
labels:
app: nodejs-app
spec:
containers:
- name: nodejs-app
image: node:19-alpine3.16
command: ["sleep", "100000"]
Run the apply command again and get the results.
kubectl apply -f ./backend/backend-kube-app.yml
kubectl get all -o wide

We're entering the final phase of deploying our application: setting up the backend database tier, which will use PostgreSQL. This phase involves several components, each crucial for the proper functioning of the database within our Kubernetes cluster:
ConfigMap:
A ConfigMap is used to store configuration data, such as usernames and passwords, separately from the application code.
This ensures better management and security of sensitive information.
In our case, we'll create a ConfigMap named
postgres-configto store PostgreSQL-related configuration data.
PersistentVolume and PersistentVolumeClaim:
These are used to define and allocate storage for the database.
PersistentVolumeClaim (PVC) is a request for storage by a user. It's used to specify the desired characteristics of the storage.
PersistentVolume (PV) is a piece of storage in the cluster that has been provisioned by an administrator.
Service:
The Service is used to enable communication with the database from other parts of the application.
It provides a stable endpoint for accessing the database.
Deployment:
The Deployment defines and manages the database pod within our Kubernetes cluster.
It ensures that the specified number of database pods are running and healthy.
In the database directory, create a new YAML file called postgres-config.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: postgres-config
labels:
app: postgres-db
data:
POSTGRES_DB: postgresdb
POSTGRES_USER: admin
POSTGRES_PASSWORD: mypass
Note 💡 Here, we're storing environment variables such as the database name, user, and password in a ConfigMap. It's essential to pay attention to the labels defined in the ConfigMap because our Deployment will use these labels to connect to the configuration.
To apply the ConfigMap to the cluster, we'll use the following command:
kubectl apply -f ./database/postgres-config.yml
To ensure that our database data persists even if the pods are terminated or restarted, we need to set up persistent storage. We'll do this by creating a PersistentVolume (PV) and a PersistentVolumeClaim (PVC) in Kubernetes.
Let's create a new YAML file named postgres-pvc-pv.yml to define both the PersistentVolume and the PersistentVolumeClaim.
Here's an example of what the YAML file might look like:
kind: PersistentVolume
apiVersion: v1
metadata:
name: postgres-pv-volume # Sets PV's name
labels:
type: local # Sets PV's type to local
app: postgres-db
spec:
storageClassName: manual
capacity:
storage: 5Gi # Sets PV Volume
accessModes:
- ReadWriteMany
hostPath:
path: "/mnt/data"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: postgres-pv-claim # Sets name of PVC
labels:
app: postgres-db
spec:
storageClassName: manual
accessModes:
- ReadWriteMany # Sets read and write access
resources:
requests:
storage: 5Gi # Sets volume size
n this YAML file:
We define a PersistentVolume named
postgres-pvwith a capacity of 10 gigabytes, using a hostPath volume type. Adjust thepathfield to specify the directory on the host machine where the data will be stored.We also define a PersistentVolumeClaim named
postgres-pvcthat requests 10 gigabytes of storage.
Apply the PV and PVC to the cluster.
kubectl apply -f ./database/postgres-pvc-pv.yml
To set up the Service and Deployment for our PostgreSQL database, we'll create a new YAML file named database-kube-app.yml and include both configurations in it. Let's break down each part:
- Service Definition:
apiVersion: v1
kind: Service
metadata:
name: postgres
labels:
app: postgres-db
spec:
type: NodePort
ports:
- port: 5432
selector:
app: postgres-db
This defines a NodePort Service named postgres exposing port 5432 for the PostgreSQL application. It ensures that traffic on this port is directed to pods labeled `app: postgres-db.
- Deployment Definition:
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-db-deployment
spec:
replicas: 1
selector:
matchLabels:
app: postgres-db
template:
metadata:
labels:
app: postgres-db
spec:
containers:
- name: postgres-db
image: postgres:10.1
imagePullPolicy: "IfNotPresent"
ports:
- containerPort: 5432
envFrom:
- configMapRef:
name: postgres-config
volumeMounts:
- mountPath: /var/lib/postgresql/data
name: postgres-volume
volumes:
- name: postgres-volume
persistentVolumeClaim:
claimName: postgres-pvc
This defines a Deployment named postgres-db-deployment with one replica. It specifies a container running the postgres:10.1 image, exposing port 5432. Environment variables are sourced from the ConfigMap postgres-config. Additionally, it mounts a persistent volume named postgres-volume from the PersistentVolumeClaim postgres-pvc to /var/lib/postgresql/data in the container.
Once the YAML file is ready, we'll apply both the Service and Deployment to the cluster using the kubectl apply -f command.
kubectl apply -f ./database/database-kube-app.yml
To test the database connection, you can use the kubectl exec command to execute a command inside one of the pods running the PostgreSQL database. Replace [pod-name] with the actual name of the pod where the database is running. Here's the command:
kubectl get all -o wide

kubectl exec -it pod/postgres-db-deployment-77777b97c9-t5pm2 -- psql -h localhost -U admin --password -p 5432 postgresdb

This command does the following:
kubectl exec -it [pod-name]: Executes a command (psql) interactively (-it) inside the specified pod.psql -hlocalhost-U admin --password -p 5432 postgresdb: Initiates a connection to the PostgreSQL database hosted onlocalhostusing the usernameadmin, with the password prompt (--password), on port5432, and connects to thepostgresdbdatabase.
After executing this command, you'll be prompted to enter the database password. Once you've entered the password, you'll be connected to the PostgreSQL database. You can then use \l to list all the databases within the PostgreSQL instance.
n summary, we've achieved the following milestones in deploying our application infrastructure with Kubernetes:
Frontend Deployment: Successfully deployed the frontend tier using a Deployment configuration, ensuring the availability of Apache HTTP Server pods.
Backend Database Deployment: Set up a PostgreSQL database backend by creating a Deployment configuration with environment variables sourced from a ConfigMap and persistent storage using PersistentVolume and PersistentVolumeClaim.
Service Configuration: Established communication between components by creating NodePort Services, exposing the necessary ports for external access.
Testing Connection: Validated the database connection by connecting to the PostgreSQL database using the
psqlclient from within a pod.Conclusion: Celebrated the successful deployment of a highly available and fault-tolerant application infrastructure with Kubernetes, highlighting the portability and scalability benefits of containerized applications managed by Kubernetes.
Cheers 🍻